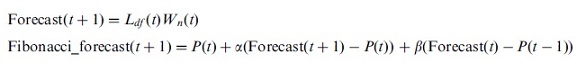※ Elliott Pattern Helper Add In
지난 글에서는 Wavelet multiresolution decomposition을 활용한 financial time-series의 dimensionality reduction에 관하여 언급했었는데요, 예측(forecasting)과 관련하여 wavelet transform에 대한 얘기를 해볼까요?
Wavelet transform을 예측에 사용하는 방법은 대략 세 가지 정도가 있는데, 첫 번째가 multiresolution analysis를 수행한 후 각각의 resolution에 대한 예측치를 계산하는 것입니다. 두 번째 방법은 wavelet을 기반으로 financial time-series의 noise를 제거한 후 예측을 하는 것이며, 세 번째는 wavelet coefficient들 자체에 예측 알고리즘을 적용하는 것입니다.
이 중 가장 자주 사용된 방법이 첫 번째 것으로서, financial time-series의 multiresolution decomposition 결과를 활용하는 아주 단순한 방법입니다. 즉, 특정 scale의 approximation layer와 그 보다 작거나 같은 scale의 detail coefficient layer 각각에 대해 예측을 수행하고 inverse transform으로 recostruction함으로써 최종 예측치를 계산하는 것이죠. (Fig 1 참조)
 |
| Fig 1. Multiresolution decomposition and forecasting |
이번 글에서는 이와 같은 방법을 담은 과거 발표 논문을 참조하여 실제로 테스트를 수행해 본 결과를 소개하도록 하겠습니다.
※ 참고 논문: Saif Ahmad, Ademola Popoola, Khurshid Ahmad, 'Wavelet-based Multiresolution Forecasting', 2005.
1. 모델링
시스템은 크게 세 부분으로 구성됩니다.
- Data preprocessing (Fig 1, 'MODWT')
- Fuzzy rule base (Fig 1, 'Build Fuzzy Rule Base')
- prediction system (Fig 1, 'Provide Forecasts', 'Aggregate Forecasts')
1.1 Data preprocessing - Multiresolution Decomposition
Wavelet multiresolution analysis를 수행하여 time-series 데이터의 시간 및 주파수(혹은 주기) 영역 특성을 추출합니다. 쉽게 설명하면, financial time-series를 추세(trend)와 계절적 cycle 및 비즈니스 cycle 등으로 분해하는 것(decomposition)이라고 보시면 됩니다.
물론, 현실 세계에서 측정한 time-series에서 추세와 여러 cycle을 정확하게 분리해 내기는 어렵겠지요? 근사치를 얻기 위해 다양한 모형을 개발해 왔으며, wavelet transform을 이용한 multiresolution decomposition은 그 중 하나가 일 뿐입니다.
논문에서는 Maximal Overlap Discrete Wavelet Transform(MODWT)과 a trous 알고리즘을 적용했습니다. MODWT에 관한 자세한 내용은 위 논문을 참고하시기 바랍니다.
1.2 Fuzzy rule base - Subtractive Clustering
Time-series 데이터에 대한 approximation 및 forecasting 시스템으로 Fuzzy Inference System(FIS)을 사용하는데, 이를 위해 fuzzy if-then rule을 생성해야 합니다. FIS의 premise parameter들을 초기화하는 것으로서, 단순하게 생각하면 input 데이터의 범위(universe of discourse)를 patitioning하고 적절한 membership function을 선택하는 과정이라고 볼 수 있습니다.
대표적인 방법으로 grid partitioning이 있는데요, universe of discourse를 균등하게 분할하고 분할된 구간들에 대해 membership function 종류와 parameter들을 수작업으로 정의하는 것이 일반적입니다.
Fuzzy if-then rule을 수작업으로 정의해야 하는 경우의 비효율성과 시행착오를 줄이기 위한 효과적인 방법이 data clustering입니다. Input data를 특정 척도(metric)에 따라 다수의 cluster로 구분하고 cluster 당 하나의 rule을 자동으로 정의합니다. Mountain clustering, subtractive clustering 등의 방법이 있으며, 위 논문에서는 subtractive clustering을 사용했습니다.
1.3 Prediction system - ANFIS
Multiresolution decomposition의 결과로 생성된 각각의 layer에 대해 예측을 수행하는 FIS로서, training 데이터로 학습(learning)을 시켜 최적화(optimization)시킨 후 실제 데이터에 대해 예측값을 계산하도록 합니다.
FIS를 학습(learining)시킨다는 것은 [input, output] 쌍으로 구성된 training 데이터를 FIS에 입력해 가면서 FIS가 계산한 output과 실제 output 간의 차이(error measure)를 줄여나갈 수 있도록 FIS의 내부 parameter들, 즉 premise parameter들과 consequent parameter들을 조정해 나가는 과정을 말합니다.
학습 알고리즘으로는 gradient descent method처럼 미분을 이용한 방법이 자주 사용되기도 하지만, local maxima를 피하기 위해 particle swarm optimization(PSO), simulated anealing(SA) 등과 같은 derivative-free 방법을 적용하기도 합니다. 2012년 9월의 포스트 'Time-Series Analysis and Forecasting'에서 소개했던 시스템이 PSO를 사용한 것이었습니다.
논문에서는 First-order (Takagi-Sugeno-Kang) TSK 타입의 FIS를 사용했다고 합니다.
2. 테스트 시스템
테스트 시스템은 위 논문에 소개된 아이디어를 적용하여 구성했습니다. 단, prediction system은 2012년 10월에 올렸던 블로그 'ANFIS and Time-Series Forecasting'에서 사용한 ANFIS 시스템을 사용했습니다. ANFIS는 premise parameter들의 최적화에 gradient descent method를, consequent parameter들에 대해서는 least square estimation(최소자승법)을 사용합니다.
Time-series의 preprocessing 모듈은 엑셀 vba로 Haar a trous 알고리즘을 구현하여 multiresolution analysis를 수행하도록 구성했으며, fuzzy rule base 자동 생성을 위해 subtractive clustering 알고리즘을 C 언어로 구현하여 기존의 ANFIS 모듈과 통합하여 사용할 수 있도록 하였습니다. 엑셀에서 엑셀 vba, vba에서 .exe 파일을 호출하는 구조입니다.
Time-Series로는 1,000 여개의 KOSPI 지수 데이터를 사용했으며, Fig 1과 같이 scale 5 레벨까지 분해(decomposition)하여 D1, D2,..., D5, S5 등 6개의 layer를 생성하여 테스트를 진행했습니다. 각각의 layer는 maximal overlap DWT를 통해 생성되었으므로 KOSPI 데이터와 동일한 갯수의 데이터를 갖는 time-series입니다.
각각의 layer에 대해, FIS는 f(Xk-n, ..., Xk-1) → Xk 처럼 연속된 lagged data만을 input으로 받아 output을 계산하도록 학습됩니다. 그렇게 [input, output] 데이터 쌍을 생성하고, 이들을 90%와 10%로 나누어 각각 training data set과 검증용(check) data set으로 나누어 테스트를 진행했습니다.
3. 테스트 결과
아래의 Fig 2-1부터 Fig 2-6까지는 scale 5 레벨 decomposition 결과로 생성된 각각의 layer에 대해 예측값을 산출한 결과입니다.
참고했던 논문에서는 각각의 layer에 대해 FIS의 input dimension을 어떻게 해야 하는지, 즉 몇 개의 lagged data를 input으로 사용해야 하는지에 대한 언급이 없었습니다. 유사한 논문들을 검색하다보니 결국은 '경험적인 방법으로 error measure를 최소화하는 input dimension을 찿는다' 였습니다. 실제로 layer 별로 dimension을 바꿔가며 테스트를 해보니, 'universal approximator'라는 ANFIS 때문인지, 3 이상에서는 별다른 차이가 없음을 알 수 있었습니다. 그래서, 모든 layer에 대해 input dimension을 3으로 설정하여 테스트를 했습니다.
Subtractive clustering parameter는 radius 0.2, squash factor 1.25, accept ratio 0.5, reject ratio 0.15를 사용했습니다.
 |
| Fig 2-1. Approximation at scale 5 (S5) |
 |
| Fig 2-2. Detail coefficients at scale 1 (D1) |
 |
| Fig 2-3. Detail coefficients at scale 2 (D2) |
 |
| Fig 2-4. Detail coefficients at scale 3 (D3) |
 |
| Fig 2-5. Detail coefficients at scale 4 (D4) |
 |
| Fig 2-6. Detail coefficients at scale 5 (D5) |
그렇다면, 모든 layer의 예측값을 합(inverse transfomation)하면 어떻게 될까요? 다음 그림 3이 그 결과입니다.
 |
| Fig 3. Reconstruction from forecasts |
D1을 noise처럼 생각하여 filtering을 한다면 어떻게 될까요? Fig 3보다는 더 정확한 결과를 얻을 수 있는 것이 당연하겠지요.
+A-F-E.jpg) |
| Fig 4. Reconstruction with D1 filtered |
Fig 3과 4를 비교해 보면 그 차이를 분명히 알 수 있습니다. 논문에서 주장하듯이 Wavelet transform에 의한 time-series preprocessing의 한 가지 이점이 확인되는군요.
4. 결 론
정리하면, Wavelet transform 기법으로 time-series를 preprocessing한 후 ANFIS를 사용하여 흐름을 예측해 본 결과, preprocessing의 효용성을 어느 정도 확인할 수 있었습니다.
참고논문에서는, 복잡한(complex) time-series를 noise나 계절적 요인 또는 추세를 제거하여 단순화시킴으로써 예측의 정확도를 높일 수 있다고 판단합니다. 실제 D1을 제거한 후의 테스트 결과(Fig 4)는 그 판단의 근거를 뒷받침합니다.
한 걸음 더 나아가, 분해된 layer들의 resolution(noise, seasonal, trend 등)에 따라 예측 기법을 상이하게 적용함으로써 예측 효과를 좀 더 향상시킬 수 있지 않을까 기대해 봅니다.